- Onko nykyinen mallisi matemaattisesti monimutkainen?
- Onko mallisi vaikeatajuinen, jopa musta laatikko?
- Vaatiiko mallisi numeronmurskausta tai superkonelaskentaa?
- Etkö tiedä, kuinka rakentaisit mallistasi yksinkertaisen ja ihmismäistä ajattelua noudattavan (numeerisen tai kielellisen) tietokonesimuloinnin?
- Haluaisitko käyttää kielellisiä arvoja ja relaatioita mallissasi?
- Haluaisitko käyttää likimääräisiä arvoja ja relaatioita mallissasi?
- Kaipaatko menetelmiä, jotka sopivat sekä kvantitatiiviseen että kvalitatiiviseen tutkimukseen?
- Haluatko rakentaa malleja, jotka toimivat hyvin käytännössä?
- Nämä ongelmat ratkeavat käyttämällä sumeaa logiikkaa (fuzzy logic) ja älykkäitä sekä oppivia järjestelmiä.
Alussa oli epätäsmällisyys
Käytämme arkipäivän elämässä koko ajan epätäsmällisiä käsitteitä ja päätelmiä. Esimerkiksi:
- Jussi on nuori
- Tämä auto on hyvin kallis
tai me päättelemme:
- Jos tämä takki on lämmin ja hinta ei ole korkea, niin ostan sen.
Tutkimustoiminnassa epätäsmälliset käsitteet ovat tyypillisiä erityisesti kvalitatiivisten metodien yhteydessä:
- Neuvostoliitolla oli suuri vaikutus Itä-Euroopan maihin
- Korkeat hinnat estävät paljon investointeja
- Venuksessa ei hyvin todennäköisesti ole elämää
Kvantitatiiviset menetelmät ovat tavallisesti pyrkineet käyttämään täsmällisiä käsitteitä, ja tähän on jossain määrin pyritty myös kvalitatiivisten metodien tapauksessa. Tämä tavoite voi kuitenkin tuottaa tiettyjä ongelmia (vrt. Sorites-paradoksi).
Epätäsmällisyyden osa-alueet
Epätäsmällisyys tarkoittaa tavallisesti kielellistä semanttista ekstensionaalista epätäsmällisyyttä, jolloin oletamme, että tietyt kielelliset ilmaisut ovat epätäsmällisiä ja että näiden ilmaisujen alat sisältävät rajatapauksia. Esimerkiksi termi nuori ihminen on epätäsmällinen, koska sen ala, nuorten ihmisten joukko, sisältää rajatapauksia, eli jotkut ihmiset eivät ole nuoria eivätkä vanhoja.
Filosofiselta kannalta epätäsmällisyyteen liittyy monia osa-alueita:

Epätäsmällisyyden osa-alueet.
Epätäsmällisyys on eri asia kuin epävarmuus. Jälkimmäinen liittyy tilanteisiin, joita emme tunne tai tiedä, ja näin ollen tieto-opillisiin kysymyksiin. Epävarmuutta tarkastellaan tavallisesti todennäköisyysteorian avulla. Esimerkiksi:
- Jussi tulee kotiin noin klo 18 (epätäsmällisyys)
- Jussi tulee todennäköisesti kotiin klo 18 (epävarmuus)
- Jussi tulee todennäköisesti kotiin noin klo 18 (epätäsmällisyys ja epävarmuus)
Täsmällisen lähestymistavan ongelmia
Kvantitatiiviset metodit pyrkivät erityisesti käyttämään täsmällisiä käsitteitä ja täsmällistä päättelyä. Joissakin tilanteissa me emme kuitenkaan voi saavuttaa näitä tavoitteita. Esimerkiksi ilmiöiden asteittaiset muutokset ovat ongelmallisia. Tunnettu tapaus on Sorites- eli Falakros-paradoksi:
10-vuotias on selvästi nuori ihminen. Pohditaan sitten:
- Jos hän on päivän vanhempi, onko hän vielä nuori?
- Jos hän on kaksi päivää vanhempi, onko hän vielä nuori?
- Jos hän on kolme päivää vanhempi, onko hän vielä nuori?
jne.
Täsmällinen lähestymistapa edellyttää, että vastaamme aina joko kyllä tai ei. Niinpä me vastaamme kyllä, kunnes saavutamme tietyn rajan (esim. 25 vuotta), ja tämän jälkeen vastaamme aina ei, koska muuten me joutuisimme väittämään, että 100-vuotiaskin on nuori. Valitettavasti tämä päättelytapa johtaa tilanteeseen, jossa 25-vuotias on nuori, mutta jo päivän vanhempi ei enää ole, ja kyseinen tilanne eli liian suuri hyppäys kategoriasta toiseen, on terveen järjen vastainen.
Yleisemmin em. päättelytapa johtaa enemmän tai vähemmän mielivaltaisten rajojen valintaan, kun asteittaisia muutoksia pyritään tarkastelemaan. Rajan alapuolella valitsemme yhden kategorian ja yläpuolella toisen. Tämän päättelyn taustalla on kaksiarvoinen logiikka, jonka mukaan väitteet ovat aina joko tosia tai epätosia.
Ongelma ratkaistaan käyttämällä moniarvologiikkaa, kuten sumeaa logiikkaa, ja silloin voimme myös käyttää toden ja epätoden välillä olevia totuusarvoja:
- 10-vuotias on nuori (tosi)
- 25-vuotias on nuori (tosi)
- 27-vuotias on nuori (melkein tosi)
- 35-vuotias on nuori (melko tosi)
- 45-vuotias on nuori (melko epätosi)
- 60-vuotias on nuori (epätosi)
jne.
Niinpä 25-vuotiaalla on täysi jäsenyys ja 35-vuotiaalla osittainen jäsenyys nuorten ihmisten joukossa, kun taas 60-vuotiaalla ei ole jäsenyyttä. Tämä ajattelutapa on perustana sumeille joukoille ja sumealle logiikalle.
Miksi meidän pitäisi käyttää sumeita malleja?
Perinteiset kvantitatiiviset mallit ovat numeerisia ja sisältävät täsmällisiä arvoja. Lisäksi ne vaativat syvällistä matemaattis-tilastollista tietoa, numeronmurskausta ja tehokkaita tietokoneita.
Kvalitatiiviset mallit, jotka ovat yleensä ei-numeerisia ja likimääräisiä, ovat olleet vaikeasti tietokoneella mallinnettavissa, ja näin ollen niiden kanssa on paljon käsin tehtävää työtä.
Sumeat (fuzzy) mallit voivat sisältää likimääräisiä arvoja ja sekä numeerista että ei-numeerista dataa. Niinpä ne ratkaisevat monia edellä mainittuja ongelmia. Sumeat mallit
- jäljittelevät ihmisen todellista päättelyä
- ovat yksinkertaisia ja helppokäyttöisiä mallin rakentamisessa
- toimivat myös monissa sellaisissa tilanteissa, joissa perinteisin menetelmin ei löydy ratkaisua
Yleisemmin älykkäät ja oppivat järjestelmät (adaptive and intelligent systems, soft computing) käsittävät sumeat systeemit, neuroverkot, todennäköisyyspäättelyn ja evoluutiolaskennan. Tietokoneympäristössä nämä metodit soveltuvat epätäsmällisyyden, oppimisen, epävarmuuden ja optimoinnin käsittelyyn. Usein erilaisia metodeja käytetään yhdessä (esim. neuro-sumeat systeemit).
Sumeiden mallien rakennuspuut
Sumeissa malleissa voidaan käyttää esimerkiksi seuraavia elementtejä:
* 5, noin 5,
* väli [4,6], noin väli [4,6],
* hyvin pieni, ei korkea, nuori tai melko nuori
* yhtä suuri kuin, likimain yhtäsuuri kuin, paljon suurempi kuin,
* funktio f(x,y)=x + y2, likimain funktio f(x,y)=x + y2,
* jos ikä on nuori, niin pituus on melko lyhyt
* etc.
Niinpä me voimme myös käyttää kielellisiä malleja ja likimääräisiä arvoja: Me voimme rakentaa malleja, joissa on kielellisiä elementtejä (pehmeä data). Esimerkiksi me voimme korvata matemaattisen funktion yksinkertaisella joukolla kielellisiä sääntöjä. Me voimme myös käyttää näitä malleja tietoympäristössä (“computing with words”). Nämä mallit voivat olla sekä lineaarisia ja epälineaarisia, ja ne kuvaavat hyvin todellisuuden ilmiöitä. Matemaattiselta kannalta sumeat systeemit ovat ns. universaaleja aproksimaattoreita, eli voimme aproksimoida minkä tahansa jatkuvan funktion mielivaltaisen tarkasti.
Sumeat ja neuro-sumeat systeemit soveltuvat hyvin sekä kvantitatiiviseen että kvalitatiiviseen tutkimukseen. Yleisemmin, voimme käyttää luonnon- ja ihmistieteiden metodeja yhdessä.
Sumeat joukot, mallinnuksen perusta
Sumea joukko-oppi (fuzzy set theory) olettaa, että oliot voivat myös osittain kuulua joukkoihin. Tavallisesti käytetään merkintätapaa, jossa 1 tarkoittaa täyttä jäsenyysastetta, arvot nollan ja ykkösen välillä osittaista ja 0 joukkoon kuulumattomuutta. Niinpä mustavalkoisen ajattelun sijasta me käytämme myös harmaan eri sävyjä. Aksiomaattiselta kannalta me hylkäämme ristiriidan periaatteen ja kolmannen poissuljetun lain.

Perinteinen joukko.

Sumea joukko.
Sumeiden joukkojen ja relaatioiden jäsenyysastetta kuvataan jäsenyysfunktion avulla, joka on kuvaus ns. perusjoukosta (reference space) E, suljetulle välille [0,1]. Niinpä perinteiset joukot ovat sumeiden joukkojen erikoistapauksia: silloin käytämme vain jäsenyysasteita 0 ja 1.
Esimerkiksi jos E on ikien joukko, voimme sanoa, että 20-vuotias, 30-vuotias ja 60-vuotias henkilö saavat vastaavasti jäsenyysasteet 1, 0.75 ja 0 nuorten ihmisten sumeassa joukossa.
Toisin sanoen:

Perinteinen nuorten ihmisten joukko.

Nuorten ihmisten sumea joukko.
Esimerkkejä sumeista joukoista
Alla on esitetty tyypillisiä sumeita joukkoja välillä E=[1,10]. Toinen ja kolmas joukko ylhäältä ovat esimerkkejä likimääräisistä väleistä.

Tyypillisiä sumeita joukkoja, kun E=[0,10].
Sumeiden joukkojen perusoperaatioita
Sumeille joukoille voidaan määrittää samanlaisia operaatioita kuin perinteisille joukoillekin. Olkoon E perusjoukko.

Sumea joukko (__) ja sen osajoukko (–).

Tässä tapauksessa siis komplementti on sumea joukko EI NOIN 5.

Sumeat joukot NOIN 5 (__) ja sen komplementti (–).
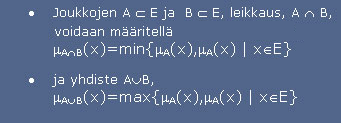

Joukkojen NOIN 5 ja NOIN 8 leikkaus (__) (ns. minimisääntö).

Joukkojen NOIN 5 ja NOIN 8 yhdiste (__) (ns. maksimisääntö).
Perinteisessä joukko-opissa joukon ja sen komplementin leikkaus on aina tyhjä joukko. Samoin joukon ja sen komplementin yhdiste on koko perusjoukko E. Nämä periaatteet tulevat kaksiarvologiikasta (ristiriidan ja kolmannen poissuljetun periaate). Sumea joukko-oppi ei noudata näitä lakeja, koska se perustuu moniarvoiseen ajatteluun ja tämän vuoksi sen avulla voidaan rakentaa käyttökelpoisempia malleja. Sumeiden joukkojen osalta voi siis olla mahdollista, että

Edellä mainituille operaatioille on paljon vaihtoehtoja, ja sopivan operaation valinta riippuu olosuhteista. Esimerkiksi päätöksenteossa käytetään erilaisia operaatioita kuin Tässä eräitä esimerkkejä:
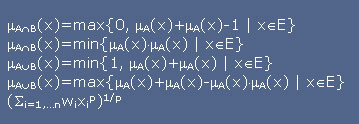
Sumeat relaatiot
Sumea relaatio voidaan esittää sellaisen jäsenyysfunktion avulla, jossa on vähintään kaksi muuttujaa. Jatkossa tarkastellaan vain kahden muuttujan funktioita, ja tällöin voimme määritellä:
Olkoon E1 ja E2 perusjoukkoja, sumea relaatio 
voidaan kuvata jäsenyysfunktiolla 
Perinteisten relaatioiden tapauksessa funktio saa vain arvoja 0 ja 1, kun taas sumea versio saa arvoja välillä [0,1]. Edellinen tapa tarkoittaa, että olioiden välillä joko on relaatio 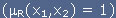
tai ei ole 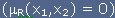 .
.
Jälkimmäisen mukaan relaatioilla voi olla eri voimakkuuksia, kuten 
(täysi voimakkuus),  (osittainen) ja
(osittainen) ja  (ei relaatiota). Niinpä perinteiset relaatiot ovat sumeiden relaatioiden erikoistapauksia.
(ei relaatiota). Niinpä perinteiset relaatiot ovat sumeiden relaatioiden erikoistapauksia.
Sumeiden relaatioiden ansiosta voimme kuvata malleissamme asioiden likimääräisiä suhteita.
Jos E1 = E2= [0,1], perinteinen relaatio  voidaan karakterisoida seuraavasti:
voidaan karakterisoida seuraavasti:
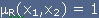 , kun
, kun
 , muuten.
, muuten.
Perinteinen relaatio . 
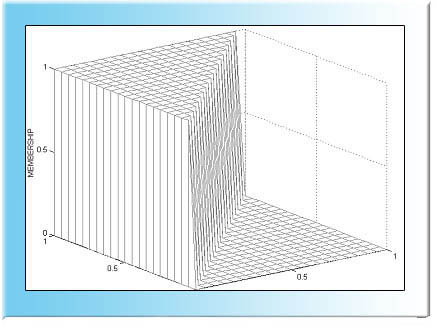
Vastaava sumea relaatio, likimäärin x1 on pienempi kuin x2, voidaan karakterisoida 
Tällöin oletimme, että jos  , x1 pienempi kuin x2 täydellä voimakkuudella, kun taas tilanteessa
, x1 pienempi kuin x2 täydellä voimakkuudella, kun taas tilanteessa  , voimakkuus on sitä pienempi, mitä suurempi on arvojen x1 ja x2, välinen etäisyys.
, voimakkuus on sitä pienempi, mitä suurempi on arvojen x1 ja x2, välinen etäisyys.
Sumea relaatio likimäärin x1 on pienempi kuin x2.
Sumeidenkin relaatioiden tapauksessa on esimerkiksi samanlaisuus- muistuttavuus- ja järjestysrelaatioita.
Mallin rakentaminen sumean päättelyn avulla
Kaksi yleisintä käytössä olevaa sumean päättelyn algoritmiä ovat Mamdani- ja Takagi-Sugeno -algoritmit, ja ne molemmat käyttävät sumeita sääntöjä.
Nämä algoritmit perustuvat kaavioon

Sumea sääntöpohjainen päättely.
- Mallissa määritetään ensin muuttujat kuten pituus, paino, aggressiivisuuden aste ja lämpötila.
- Määritetään muuttuja-arvot: 150, noin 150, 10-20, noin 10-20, hyvin korkea, huono tai hyvin huono, ei nuori jne.
- Teemme sumeat säännöt, jotka perustuvat asiantuntijoiden tietoon, empiirisiin aineistoihin tai molempiin. Voimme käyttää säännöissä sidesanoja, kuten ja ja tai.
- Käytämme päättelyalgoritmiä, joka tuottaa tulosteita em. sääntöjen ja syötteiden avulla.
- Voimme testata ja arvioida mallin hyvyyttä. Erillistä aineistoa voidaan käyttää tähän tehtävään. Mallia voidaan myös virittää paremmaksi käyttämällä esim. neuroverkkoja.
Sumeiden sääntöjen tuottaminen
Sumeita sääntöjä tuotetaan asiantuntijoiden tietojen ja/tai empiiristen aineistojen perusteella. Molemmissa tapauksissa pyritään tarkasteltava ilmiö esittämään pienellä joukolla yksinkertaisia sääntöjä.
Jos empiiristä aineistoa on käytössä, meidän pitäisi käyttää perusjoukkoa hyvin edustavaa aineistoa. Aineiston koko riippuu mm. sääntöjenmuodostamistavasta, perusjoukon koosta, aineiston homogeenisyydestä, tarkasteluavaruuden ulottuvuuksien määrästä, mallin tavoitteista ja mallin virhemarginaaleista.
Esimerkiksi jos muodostamme säännöt kaikista syöte- ja vastearvojen yhdistelmistä (grid partition technique), tarvitsemme suuren aineiston ja melko paljon laskentatehoa. Jos yksi syötemuuttuja – yksi vastemuuttuja edellyttää kymmentä havaintoa, niin neljä syöte- neljä vastemuuttujaa edellyttää jo 103 = 1000 havaintoa. Mitä tulee sääntöjen määrään, neljä muuttujaa, joista jokainen saa kolme eri arvoa, tuottaa malliin jo 34 = 81 sääntöä.
Jos käytämme sääntöinä aineiston havaintoklusterien (so. ryhmien) keskuksia (scatter technique), sääntöjen määrä on tavallisesti pienempi, mutta tällöin malli voi tuottaa epätyydyttäviä tuloksia tiettyjen klusterialuiden ulkopuolella (ns. ekstrapolaation ongelma).
Jos aineisto on riittävän iso, voimme ratkaista em. ongelmia jakamalla sen satunnaisesti opetusaineistoksi ja vertailuaineistoksi. Edellisen avulla rakennamme mallin ja jälkimmäisen avulla tutkimme sen hyvyyttä. Tällöin mallia voidaan käyttää yleisemmin eri tilanteissa. Tyypillinen ylideterminoitumisen ongelma esiintyy silloin, kun malli toimii opetusaineiston kanssa hyvin, mutta antaa vertailuaineiston kanssa huonoja tuloksia. Meidän on muistettava, että aineistojen avulla rakennetut mallit toimivat hyvin vain sillä alueella, mistä aineistoa on saatavilla, ekstrapolaation ongelmaa ei mikään malli ratkaise
Jos empiiristä aineistoa ei ole saatavilla, mallin rakentaminen voi olla työläämpää.
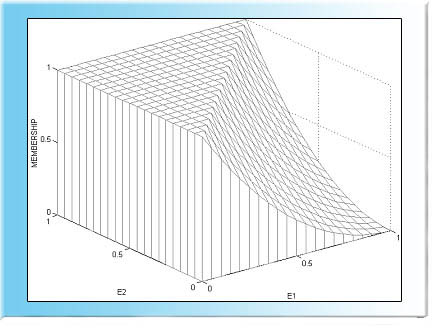
Alla on standardoitua normaalijakaumaa kuvaava aineisto. Hyödyntämällä aineiston ryhmien keskuksia (Subclust-algoritmi) voimme muodostaa halutun määrän sääntöjä.

Kolmen klusterikeskuksen (säännön) ratkaisu.
Viiden säännön ratkaisu.
Esimerkki sumeasta mallinnuksesta
Oletetaan, että meidän pitää ostaa keskikokoinen auto käyttämällä kahta kriteeriä, hinta ja polttoaineen kulutus. Niinpä meillä on päätösmalli, jossa käytämme kahta syöte- ja yhtä vastemuuttujaa.
Käytämme seuraavia kielellisiä arvoja:
- Hinta on asteikolla USD 15 000 to 25 000, kielelliset arvot ovat halpa (n. 15 000), keskihintainen (n. 20 000) ja kallis (n. 25 000).
- Polttoaineen kulutus on asteikolla 5 l/100 km – 15 l/100 km, ja käytämme arvoja matala, (n. 5 l/100 km), keskinkertainen (n. 10 l/100 km) ja korkea (n. 15 l/100 km).
Päätöksemme (vaste) tehdään asteikolla -1 – 1, missä mm. noin -1 = huono, noin 0 = ei huono eikä hyvä ja noin 1 = hyvä.
Jos aineistoa ei ole käytössä, malli perustuu vain asiantuntemukseen. Esimerkiksi voimme muodostaa seuraavat säännöt:
- Jos hinta on halpa ja kulutus on pieni, niin valintamme on hyvä.
- Jos hinta on kallis ja kulutus on suuri, niin valintamme on huono.
- Jos hinta on halpa tai kulutus on pieni, niin valintamme on melko hyvä.
Nämä säännöt ja Mamdani-päättely tuottavat seuraavan päätöspinnan:

Päätöspinta auton ostoon, Mamdani-päättely.
Huomaamme, että säännöt tuottavat meille epälineaarisen mallin, mikä on tyypillistä sumeille malleille: muutamalla säännöllä voimme kuvailla monimutkaisiakin epälineaarisia ilmiöitä.
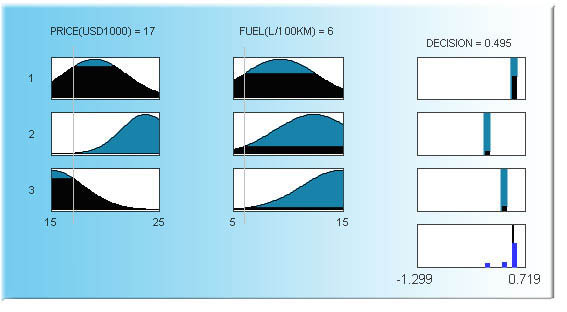
Seuraava kuva esittää, kuinka em. päättely tapahtuu. Sääntöjen etujäsenet on painotettu syötteiden (pystyviivat) perusteella. Painot ovat sitä suuremmat, mitä enemmän syötteet muistuttavat etujäseniä. Jos etujäsen koostuu useasta osasta (kuten edellä kahdesta), lopullinen paino on aina painojen minimi (kun ja) tai maksimi (kun tai). Lopulliset painot ovat sitten takajäsenien painoja. Vastearvo perustuu sitten takajäseniin ja niiden painoihin. Esimerkiksi alla se on painotettujen takajäsenien joukko-opillinen yhdiste.

Esimerkiksi jos syötteet ovat n. USD 17 000 ja n. 6 l/100 km (harmaat pystyviivat), kolmas sääntö saa täyden painon, ensimmäinen osittaisen painon ja toinen sääntö ei ole mukana päättelyssä. Päätös on näin ollen (alla oikealla) painotettujen takajäsenten maksimi. Saamme myös vastaavan täsmällistetyn arvon, joka on vastejoukon painopiste (0,495, paksu pystypalkki oik. alh.). Voimme käyttää monenlaisia täsmällistämismetodeja:
Sumeat säännöt auton ostoon (Mamdani-päättely):
Oletetaan nyt, että meillä on empiirinen aineisto käytettävissä siitä, kuinka ihmiset tekevät päätöksiä auton ostossa. Tämä aineisto on seuraavassa kuvassa:
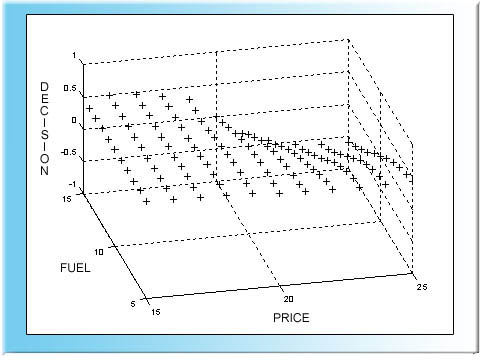
Empiirinen aineisto auton ostoon.
Ensin sovellamme lineaarista regressioanalyysiä tähän aineistoon. Tällöin saamme seuraavan mallin:
Päätös = -0.07hinta – 0.05kulutus + 2.07
Vastaava päätöspinta on taso:
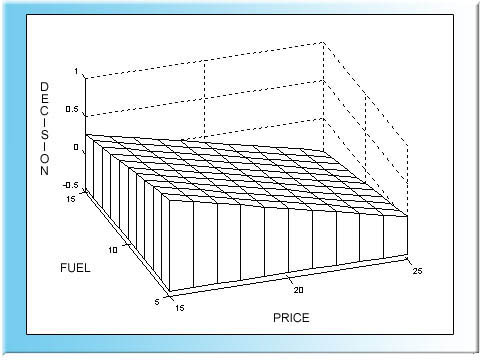
Lineaarisen regressioanalyysin päätöspinta auton ostoon.
Seuraava kuvio osoittaa, että em. malli ei ole kovin hyvä, sillä muun muassa aineisto näyttääkin olevan epälineearinen luonteeltaan.

Mallin hyvyys, lineaarinen regressioanalyysi.
Toiseksi seuraava epälineearinen matemaattinen malli:
Päätös = -1.4325 + 0.1327hinta + 0.2612kulutus – 0.0133hinta × kulutus-0.0016hinta2 – 0.0023kulutus2
Tämä malli on parempi kuin edellinen, mutta se on matemaattisesti paljon monimutkaisempi.

Mallin hyvyys, epälineaarinen matemaattinen malli.
Jos me sovellamme Takagi-Sugeno -päättelyalgoritmia, tuotamme sumeat säännöt dataklustereiden keskusten perusteella esimerkiksi Subclust-algoritmilla. Klusterien keskusten perusteella tuotamme sitten lopulliset säännöt. Tässä yhteydessä käytämme kolmea sääntöä:
Hinta noin; Kulutus noin; Päätös noin
- 19000; 9; 0.4367
- 23000; 12; -0.2221
- 15000; 15; 0.4959
Takagi-Sugeno –päättely muokkaa näitä alkuperäisiä sääntöjä korvaamalla takajäsenet lineaarisilla funktioilla. Niinpä se käyttää sääntöjä, jotka ovat tyyppiä:
Jos hinta on noin 19 000 ja kulutus on noin 9, niin päätöksen hyvyys on noin f(hinta,kulutus), jossa f on lineaarinen funktio.
Seuraava kuva esittää edellä mainittua päättelyä. Takajäsenet ovat reaalilukuja (funktion f arvoja), ja niitä on painotettu syötteiden ja etujäsenien avulla samalla tavoin kuin Mamdani-päättelyssäkin. Lopullinen päätös (musta palkki alh. oik.) on takajäsenien painotettu summa.
Sumeat säännöt auton ostoon (Takagi-Sugeno -päättely).

Seuraavan kuvion perusteella Takagi-Sugeno –malli näyttää olevan hyvä:

Mallin hyvyys (Takagi-Sugeno -päättely).
Sumeita sääntöjä voidaan virittää esimerkiksi neuroverkkojen avulla, jos emme ole tyytyväisiä malliimme. Kun edellä olevaa Takagi-Sugeno –mallia viritettiin neuro-sumean Anfis-algoritmin avulla (mikä muokkaa mallin sumeita sääntöjä), malli saatiin hieman paremmaksi.

Mallin hyvyys (Anfis neuro-sumea päättely).
Viritetyt säännöt auton ostoon (Anfis neuro-sumea päättely).
Tämä malli tuottaa samanlaisen päätöspinnan kuin edellä esitetty Mamdani-mallikin, koska ”empiirinen” aineistomme oli itse asiassa tuotettu Mamdani-mallin avulla. Sumeat mallit yleensä tuottavatkin ns. oikean pinnan.
Mallin hyvyttää voidaan tarkastella myös vertailuaineiston avulla.
Monimutkaisten systeemien sumeat mallit
Usein joudumme tarkastelemaan malleja, joissa on paljon muuttujia tai moduuleja sekä vaikeasti kuvattavia relaatioita näiden elementtien välillä. Esimerkkeinä voidaan mainita suhteikot (graphs), neuroverkot, miellekartat, Bayes-verkot, semanttiset verkot ja käsitekartat. Me käytämme näitä malleja sekä ilmiöiden selittämiseen että ennustamiseen, ja tietokoneympäristössä niiden avulla voidaan suorittaa erilaisia simulointeja.
Perinteiset lähestymistavat soveltavat matemaattisia malleja ja ne ovat laskennallisesti raskaita jopa tietokoneelle. Vastaavat sumeat mallit, jotka ovat yksinkertaisempia, voivat sisältää myös kielellisiä ja/tai likimääräisiä muuttujia ja relaatioita, ja niinpä ne soveltuvat myös sellaisiin kvalitatiivisen tutkimuksen tilanteisiin, joita ei ole aikaisemmin voitu simuloida tietokoneella. Kyseisiä sumeita malleja kutsutaan joskus sumeiksi kognitiiviksi kartoiksi (fuzzy cognitive maps).
Monimutkainen malli on siis tyyppiä

Esimerkki monimutkaisesta mallista.
Ympyrät (nodes) ovat tavallisesti muuttujia, ja niiden välillä on erilaisia (kausaali)relaatioita. Kun muuttujille on asetettu alkuarvot, me voimme simuloida, kuinka arvot mallissa muuttuvat relaatioiden vaikutuksesta. Kun yhden muuttujan arvo muuttuu, se voi vaikuttaa useiden muiden muuttujien arvoihin, ja näin ollen koko verkosto reagoi muutoksiin. Tällaiset simulaatiot ovat hyvin vaikeasti toteutettavissa
Sumean logiikan ansiosta muuttujien väliset relaatiot voidaan kuvata sumeiden sääntöjoukkojen avulla, joihin sitten sovelletaan esimerkiksi Mamdani- tai Takagi-Sugeno –päättelyä. Niinpä nämä mallit sisältävät yleensä useita sumeita päättelymoduuleja. Lisäksi tarvitaan yk-sinkertainen moduuli, joka valvoo, minkä muuttujan arvo milloinkin vaihdetaan.

Muuttujien väliset relaatiot voidaan kuvata sumeiden sääntöjen avulla.
Kun nämä mallit hyödyntävät sumeaa logiikkaa, ne ovat hyvin käyttökelpoisia monissa luonnontieteiden ja ihmistieteiden sovelluksissa. Samoin niitä voidaan soveltaa hypertietämyksen ja hypermedian esittämiseen. Jälkimmäisessä tapauksessa älykkäillä www-sovelluksilla, kuten e-oppiminen, e-business ja webbirobotit, on edessään erittäin hyvät näkymät.
Sumeita kognitiivisia karttoja voidaan soveltaa myös virtuaalimaailmoihin ja keinoelämään. Virtuaalimaailmassa on aineettomia olioita, jotka ovat vuorovaikutuksessa keskenään. Unien maailma on klassinen esimerkki virtuaalimaailmasta.
Adaptiiviset sumeat kognitiiviset kartat voivat oppia muuttujien väliset säännöt annetun ”historiadatan” perusteella.
Niskanen, Vesa A. 2004. Sumean logiikan käyttö mallinnuksessa, lyhyt oppimäärä. www.metodix.com. Menetelmäartikkelit
Kirjallisuutta
H. Bandemer & W. Näther, Fuzzy data analysis (Kluwer, Dordrecht, 1992).
J. Bezdek & S. Pal, Fuzzy models for pattern recognition (IEEE Press,
New York, 1992).
S. Chiu, Fuzzy model identification based on cluster estimation, Journal
of Intelligent and Fuzzy Systems, 2 (1994) 267-278.
H. Dyckhoff & W. Pedrycz, Generalized means as model of compensative
connectives, Fuzzy Sets and Systems 14 (1984) 143-154.
R. Jang, ANFIS: Adaptive-network-based fuzzy inference system, IEEE
Transactions on Systems, Man and Cybernetics 23/3 (1993) 665-685.
W. Kickert, Fuzzy theories on decision making (Nijhoff, Boston, 1978).
B. Kosko, Fuzzy Engineering (Prentice Hall, New Jersey, 1997).
R. Krishnapuram & J. Lee, Fuzzy-connective-based hierarchial aggregation
networks for decision making, Fuzzy Sets and Systems 46/1 (1992) 11-28.
J. Mattila, Sumean logiikan oppikirja (Art House, 1997).
A. Niemi, Johdatus sumeisiin joukkoihin ja sumeaan logiikkaan
(Opetushallitus, 1996).
V. A. Niskanen, A brief logopedics for the data used in a neuro-fuzzy
milieu, in Ralescu, A. & Shanahan, J (Eds.): Fuzzy logic in artificial
intelligenc”, Lecture Notes inArtificial Intelligence 1566, Springer Verlag,
Berlin, 1999, pp. 222-233.
V. A. Niskanen, Prospects for Soft Statistical Computing: Describing
Data and Inferring from Data with Words in the Human Sciences, Information
Sciences, vol. 132, 2001, 83-131.
V. A. Niskanen, Sumea logiikka – kirkasta älyä ja mallinnusta. WSOY, 2003.
V. A. Niskanen, Soft Computing Methods in Human Sciences. Series: Studies in Fuzziness and Soft Computing , Vol. 134. Springer-Verlag. Berlin, 2003 (http://www.springeronline.com/sgw/cda/frontpage/0,10735,5-40109-22-3054388-0,00.html).
V. A. Niskanen, The unbearable lightness of neuro-fuzzy multi-criteria
decision making, in: P. Walden & al., Eds., The Art and Science of Decision
Making (Painosalama, Turku, 1996), 168-178.
H. Puolakka, Sumea logiikka käytännön sovelluksissa (Opetushallitus,
1997).
M. Smithson, Fuzzy set analysis for behavioural and social sciences
(Springer Verlag, New York, 1987).
T. Takagi & M. Sugeno, Fuzzy identification of systems and its
applications to modeling and control, IEEE Transactions on Systems, Man and
Cybernetics, SMC-15/1 (1985) 116-132.
R. Yager & D. Filev, Generation of fuzzy rules by mountain clustering,
Journal of Intelligent and Fuzzy Systems 2 (1994) 209-219.
L. Zadeh, From Computing with Numbers to Computing with Words – From
Manipulation of Measurements to Manipulation of Perceptions, IEEE
Transactions on Circuits and Systems 45, (1999) 105-119.
L. Zadeh, Fuzzy logic = Computing with words, IEEE Transactions on
Fuzzy Systems, vol. 2, pp. 103-111, 1996.
L. Zadeh, Toward a theory of fuzzy information granulation and its
centrality in human reasoning and fuzzy logic, Fuzzy Sets and Systems 90/2
(1997) 111-127.
H.-J. Zimmermann, Fuzzy Set Theory and Its Applications (Kluwer,
Boston, 1991).
Linkkejä
Springerin kirjoja: www.springer.com
Kluwerin kirjoja: http://www.wkap.nl/series.htm/FSHS
Journal of Fuzzy Sets and Systems: http://www.elsevier.com/locate/issn/01650114
IEEE Transaction of Fuzzy Systems: http://www.ewh.ieee.org/tc/nnc/pubs/tfs/
International Journal of Approximate Reasoning: http://www.journals.elsevier.com/international-journal-of-approximate-reasoning/
Lisää kirjoja ja aikausilehtiä: http://www.pa.info.mie-u.ac.jp/~furu/ifsa/
Tekesin raportti ”Sumean logiikan mahdollisuudet”: http://www.tekes.fi/julkaisut/sumea/index.html
Vesa Niskasen materiaali: http://www.honeybee.helsinki.fi/users/niskanen/sumeaesi/index.htm
Vesa Niskasen kesäkoulun materiaali: http://www.helsinki.fi/~niskanen/sc2001/sc2001.html
International Fuzzy Systems Association (IFSA):
http://isdlab.ie.ntnu.edu.tw/ntust/ifsa/
BISC Group (UC Berkeley, USA, alan johtava ryhmä maailmassa):
http://www-bisc.cs.berkeley.edu/
Matlabin neuroverkko-ohjelma:
http://www.mathworks.com/products/neuralnet/index.shtml
Kohosen Websom-ohjelma: http://lipas.uwasa.fi/stes/step96/step96/lagus/
Matlabin sumean logiikan ohjelma: http://www.mathworks.com/products/fuzzylogic/
Fuzzytechin neuro-sumea ohjelma: http://www.fuzzytech.com/
Sumean kognitiivisen kartan ohjelma: http://www.fuzzysys.com/ftaprod.html
Yhteystiedot
Vesa A. Niskanen
FT, Dosentti
Helsingin yliopisto
Tenerum OY
puh. 040 503 2031
e-mail vesa.a.niskanen@helsinki.fi
http://www.mv.helsinki.fi/home/niskanen/
Kategoriat:artikkeli, Artikkelit

Jätä kommentti